First of all then - what is Lookup caching?
Back in Integration Services 2005 there was a transformation task which allowed you to match a record in the dataflow with record or field in a database via an OLE DB connection. In a data warehouse context this was often used to look up surrogate keys when loading fact tables. This was OK but every time a lookup was needed it required a round-trip to the database. If you're loading a data warehouse with role-playing dimensions you might be looking up the same values for the same fact table, in the same dataflow. There were some options for preformance-tuining but essentially you always had to connect to the database in some way every time. Inefficient and in stark contrast to products such as Informatica which allowed you to reuse lookup data cached in memory.
So what changed in 2008?
For 2008 Microsoft substantially improved lookup functionality. You now have two basic caching options for lookups. These boil down to in-memory caching and file caching. Both are potentially faster than lookups using a database.
In this post we'll deal with memory-caching.
As the name suggests this stores the lookup data in-memory (ie RAM). This is pretty well covered by Jamie here . The key point is that the in-memory cache will not extend beyond the scope of the package ie you can't re-use an in-memory cache in one package having created in another. At this point its worth clarifying how this is used in a package.
Step one:
After you've created a connection manager, the first step is to create a data source in a Data Flow Task - in this example it is an OLEDB Source Transformation. Note you can use any source for this - providing another advantage over using the 2005 look-up task on its own. I'm calling this OLEDB_Dim_Time for obvious reasons:

Step two:
The next step is to terminate the data flow in the Cache Transform - which caches in memory.
The Cache Transform Editor looks as follows:

Here you need to create a cache connection manager by clicking the New... button. This then displays the Cache Connection Manager Editor, give the Cache Connection Manager a sensible name - in this case 'TimeLKP', and click on the 'Columns' tab:



All thats left is to use the Cache Connection Manager in a Lookup Transform.

Then choose your Cache connection:

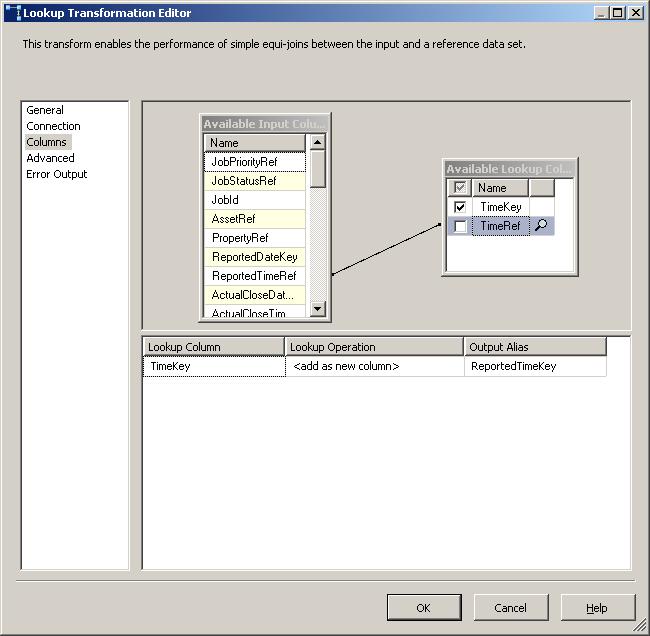
Hopefully thats clarified how to go about creating an in-memory lookup cache. In my next post I'll demonstrate creating a file-cache and share the results of my entirely unscientific performance comparison of memory-caching vs file-caching vs
No comments:
Post a Comment